Context
When you work in the commercial team of a product-based company, you tend to spend a lot of time with PowerPoint. Especially in a place where newer products are always coming up. I had a similar experience when I joined Qure.ai. I frequently ended up making custom presentations based on the client I’m talking to. In most cases, I know someone must have made this slide already but I’m not sure who did and when. I would go on our slack channel and check; someone would respond after a sometime with one ppt that probably has the slide I need. Obviously, this is not ideal, and neither is having a central repository of all the presentations (no way of finding where the slide I need is). That is when I started to think about working on ‘SIR - Slide Identifier and Retriever’ and the following is what I learnt while making it
What SIR does
The idea is to maintain a central repository of all the presentations keep updating it as more are made. The slide finder will search though all these presentations whenever someone searches for something (Keyword search) and returns a new presentation with all the matching slides. Even though it is straight forward, this is my first such project. So, this blog is going to be on the theme of figuring how to execute such an idea and structuring the project.
The final objective looks somewhat like this - a user types in a keyword and a new PPT with relevant slides is saved in the target directory
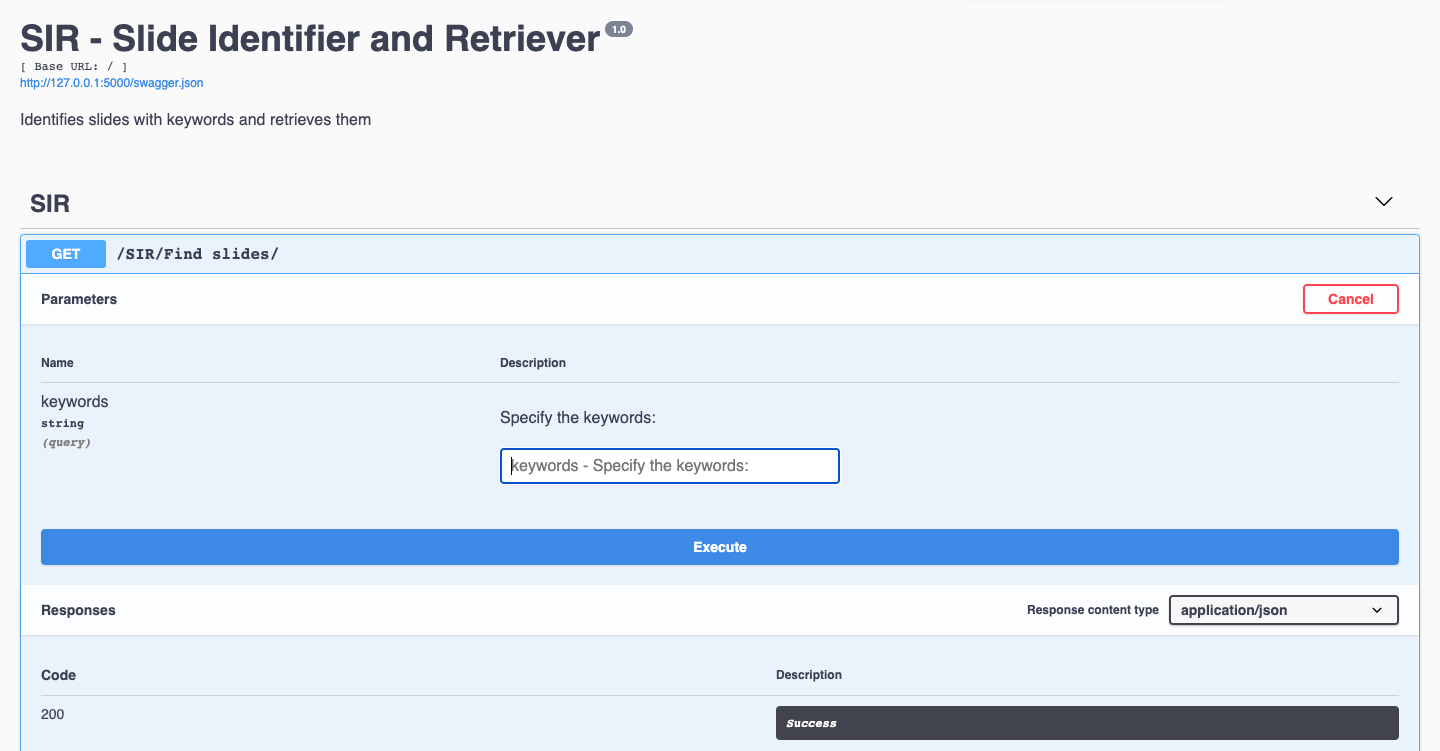
A demo UI made using Flask
The following are the main components that we need to figure out:
- Understanding how to read and manipulate
*pptx files in python
- Matching the slides that contain the Keywords searched
- Creating a new ppt using the relevant slides
Understanding how to read and manipulate *pptx in python
This is probably the easiest of the steps. Although there are few modules to do this, python-pptx works here best with the latest version of python without many hiccups. Unfortunately, the module is fairly new and has limited functionality but for now, it achieves the objective - you can open a ppt, read through each slide, identify the shapes in and get the text inside the text boxes.
Matching the slides that contain the Keywords searched
After consulting an expert on the topic (a friend of mine), I realised that I was using a hard constraint to match the keywords with the text in the slide. So naturally he suggested some of the state-of-the-art NLP algorithms that can detect sentence similarity.
- First of them is BERT:
BERT, which stands for Bidirectional Encoder Representations from Transformers is a state-of-the-art machine learning framework for Natural Language Processing (NLP) designed by researchers at Google AI Language. Using on the pre-trained BERT models, we can obtain a similarity score between two sentences. The speciality of BERT is that it can read the whole sentence at once (Bi-directional) and understand words based on context (bank in bank balance vs river bank). We give the input as word embeddings (mathematical vector representations of words) meaning similar words are considered as one.
from transformers import BertTokenizer, BertModel
import torch
segment_ids=[1]*len(tkt)
tokens_tensor = torch.tensor([tkt])
segments_tensors = torch.tensor([segment_ids])
model = BertModel.from_pretrained('bert-base-uncased',output_hidden_states = True)
model.eval()
with torch.no_grad():
outputs = model(tokens_tensor, segments_tensors)
hidden_states = outputs[2]
I soon realised BERT is an overkill for my use case. It is computationally expensive, and I faced issues like 1. My search hugely depends on product names (ex: qXR and qER), BERT doesn’t differentiate well enough between them and 2. I usually end up comparing sentences of different length and BERT takes that into account when calculating similarity (at least the basic implementation I have does) brining up issues with the threshold I can use.
- TF-IDF:
This is a huge stepdown in terms of complexity but is closer to what we need here. TF-IDF has two components TF - term frequency (how many times a word occurs in a slide/document) and IDF - inverse document frequency (How rarely it occurs overall). Each word will this TF-IDF score - rarer words having higher. If you need more information, this excellent post, which is part of an NLP beginner series, explains it better. This works great when you compare two sentences to understand how similar they are even if they are of different lengths. It is still not suitable here because assigning less score to frequent words may not be very useful for a keyword search (product names again are frequent so deprioritized). However, this is perfect for solving another issue we will come against - more on that later.
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
vectorizer.fit(corpus)
print(vectorizer.transform(text).toarray())
- Bag of Words (BoW):
This turned out to be my Occam’s razor. The simplest of the three works best for my use case. Bag of Words simply looks at occurrence of words in any given sentence. This was best suited to figure out which slides have the key words searched. Sure, it will miss synonymous words or semantical meanings, but it works here. People searching for a slide know what they want, and it serves best if we keep it simple.
from keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(corpus)
vectorizer.texts_to_matrix(text,mode="count")
For any of these models to work well, we need to pre-process the text we are using. Some obvious ones are making everything lower cased, removing stop words (common words like - is, are, the), removing punctuation. I also used stemming (reducing the words to simplest form - played, playing, plays all are replaces with play) and removed duplicate words withing a paragraph (easier implementation with BoW).
The lesson learnt here is, though there are hundreds of ways of achieving an objective, understanding your use case in depth will help you easily figure out which works best. However, the best part of the project is figuring this out as it allows me to learn a lot of new things that can be useful later.
Creating a new ppt using the relevant slides:
We come across a new challenge when we start picking up slides to make a new ppt. Since the repository has all the slides ever created, there are bound to be duplicates of slides. We ideally want to delete them, and this is where TF-IDF is perfect. BoW does not consider lenth of the sentences we are comparing either, but TF-IDF does. So, I used it to figure out if any of the slides are repeating. But like I mentioned, the python-pptx has some serious limitations right now. One of them is copying slides from one presentation to another - which is exactly what we are trying to do. There may be few more modules that can do this, but I couldn’t install them for my python version (3.8.5). This is the best workaround I could find to do this (still with some limitations)
def _get_blank_slide_layout(pres):
layout_items_count = [len(layout.placeholders) for layout in pres.slide_layouts]
min_items = min(layout_items_count)
blank_layout_id = layout_items_count.index(min_items)
return pres.slide_layouts[blank_layout_id]
def duplicate_slide(pres, index):
"""Duplicate the slide with the given index in pres.
Adds slide to the end of the presentation"""
source = pres.slides[index]
blank_slide_layout = _get_blank_slide_layout(pres)
dest = pres.slides.add_slide(blank_slide_layout)
for key, value in six.iteritems(source.rels):
# Make sure we don't copy a notesSlide relation as that won't exist
if not "notesSlide" in value.reltype:
dest.rels.add_relationship(value.reltype, value._target, value.rId)
for shp in srource.shapes:
if shp.shape_type == MSO_SHAPE_TYPE.PICTURE:
with open(shp.name+'.jpg', 'wb') as f:
f.write(shp.image.blob)
imgDict[shp.name+'.jpg'] = [shp.left, shp.top, shp.width, shp.height]
else:
el = shp.element
newel = copy.deepcopy(el)
dest.shapes._spTree.insert_element_before(newel, 'p:extLst')
for k, v in imgDict.items():
dest.shapes.add_picture(k,v[0], v[1],v[2],v[3])
os.remove(k)
return dest
References:
- (https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270)
- https://medium.com/@samia.khalid/bert-explained-a-complete-guide-with-theory-and-tutorial-3ac9ebc8fa7c
- https://medium.com/nerd-for-tech/nlp-zero-to-one-sparse-document-representations-part-2-30-d7ce30b96d63
- https://github.com/scanny/python-pptx/issues/132
- https://stackoverflow.com/questions/50866634/python-pptx-copy-slide